Smartup: Agencia de Marketing Digital y Big Data
CRISP-DM: los 6 pasos del proceso de Data Mining

Cuando se lleva a cabo un proyecto, independientemente de si se trata de un proyecto grande o pequeño, siempre se han de utilizar técnicas y herramientas que nos ayuden a su planificación, desarrollo y mantenimiento. Frameworks como el Proceso Unificado (UP) o Scrum son estándares hoy en día en cualquier proyecto software y, en el caso de los proyectos Big Data, tenemos metodologías KDD (Knowledge Discovery in Databases) como CRISP-DM (Cross Industry Standard Process for Data Mining) y SEMMA (Sample, Explore, Modify, Model, and Assess) que nos ayudan a encontrar conocimiento en nuestros datos. De estas metodologías, CRISP-DM es la más utilizada, al enfocar sus resultados al entorno de negocio. En este post os vamos a explicar en qué consiste y cuáles son los pasos del proceso de Data Mining.
De manera parecida a UP y Scrum, CRISP-DM define un ciclo de vida enfocado a la exploración y análisis de los datos. Este ciclo de vida consta de 6 fases: Comprensión del negocio, Comprensión de los datos, Preparación de los datos, Modelado, Evaluación y Despliegue. A continuación os describimos cada una de las fases:
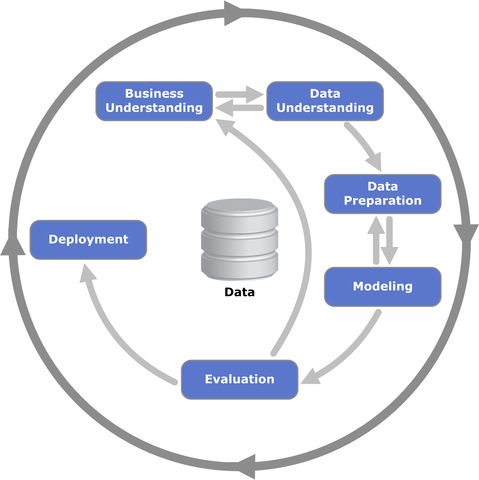
1. Compresión del negocio
Esta fase inicial se enfoca en la comprensión de los objetivos y exigencias del proyecto desde una perspectiva de negocio. Posteriormente convierte ese conocimiento de los datos en la definición de un problema de minería de datos y en un plan preliminar diseñado para alcanzar los objetivos.
2. Comprensión de los datos
La comprensión de los datos se encarga de la recolección de datos inicial y continúa con las actividades que permiten familiarizarse primero con los datos, identificar sus problemas de calidad, descubrir conocimiento preliminar en los mismos, y/o descubrir subconjuntos interesantes para formular hipótesis. En esta fase se tienen en cuenta también las fuentes de datos que hasta el momento no se estaban utilizando (fuentes externas, …).
3. Preparación de los datos
La fase de preparación de los datos cubre todas las actividades necesarias para construir el conjunto de datos final (los datos que serán provistos por las herramientas de modelado). Las tareas de preparación incluyen la selección de los datos, la limpieza de éstos, la construcción de nuevas variables, la integración de los datos y el formateo de los mismos.
4. Modelado
Durante esta fase, se aplican las técnicas de minería de datos a nuestros datos. Se aplican varias técnicas de modelado y los parámetros de uso de las mismas se afinan hasta alcanzar los valores óptimos. Algunas técnicas de modelado necesitan requerimientos específicos sobre el formato de los datos, que podrán llevarnos de nuevo a la fase de preparación de los datos.
5. Evaluación
En este caso se evalúan los modelos anteriores para determinar si son útiles a las necesidades de negocio. En esta etapa los modelos ya están construidos y deben tener una alta calidad desde una perspectiva de análisis de datos.
6. Despliegue
La fase de despliegue implica la explotación de los modelos dentro de un entorno de producción. La creación de un modelo no es generalmente el final del proyecto, ya que su creación es un proceso vivo dentro del proceso de decisiones de una organización (podría ser necesario rehacer el modelo para tener en cuenta nuevo conocimiento en el futuro).
El uso de metodologías como CRISP-DM en proyectos Big Data no sólo agilizará su desarrollo, sino que, además, nos asegura calidad en los datos con los que trabajamos y los resultados que obtengamos. Desde Smartup os animamos a que utiliceis CRISP-DM en vuestros proyectos de Big Data.
![]() Otros artículos que te interesarán
Otros artículos que te interesarán

La Vecina Rubia, la influencer que todas las marcas querrían fichar
Tiempo de lectura: 6 minutos En Smartup, Agencia de Marketing Digital, analizamos el reinado de La Vecina Rubia en las RRSS y por qué todas las marcas querrían trabajar con ella.

Subvención para el mantenimiento del empleo, la transición ecológica y la transformación digital
Tiempo de lectura: 3 minutos Smartup ha recibido una subvención destinada a la financiación de los proyectos incluidos en la inversión 4 “Emprendimiento y Microempresas”, del componente 23 “Nuevas políticas públicas para un mercado de trabajo dinámico, resiliente e inclusivo”

Webinar: Automatización e Inteligencia Artificial para la Excelencia Empresarial con Exact
Tiempo de lectura: 4 minutos En un mundo empresarial en constante evolución, la adopción de la tecnología es fundamental para mantenerse competitivo. La inteligencia artificial (IA) y la automatización han emergido como poderosas fuerzas impulsoras de la eficiencia y la innovación en el ámbito corporativo. Por ello, exploraremos la relación entre automatización e inteligencia artificial en un apasionante webinar organizado por el CEO de Smartup, David Ruiz, junto a Exact.
Smartup 2019 © Todos los derechos reservados.